Harry Potter and the Goblet of Fire Project
Methodology
Our team tagged the characters, chapters, scenes, creatures, and spells of both the "Harry Potter and the Goblet of Fire" book and movie script.
We then put it into xslts to filter the html pages. We sought to compare the amount of characters, creatures, and spells in each chapter in the book
and each scene in the movie.
XSLT FOR NOVEL CHARACTER/CREATURE/SPELL ANALYSIS:
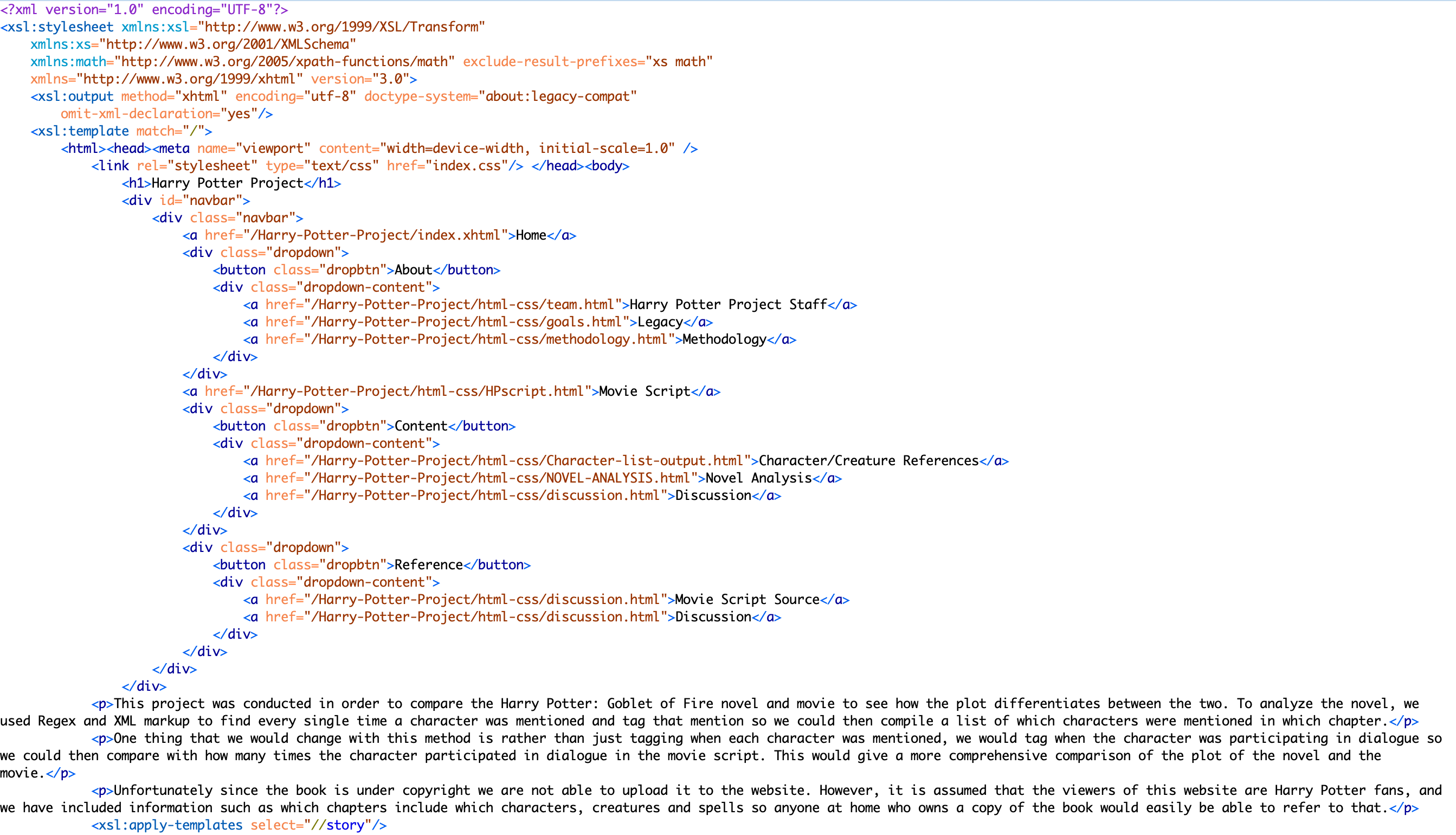
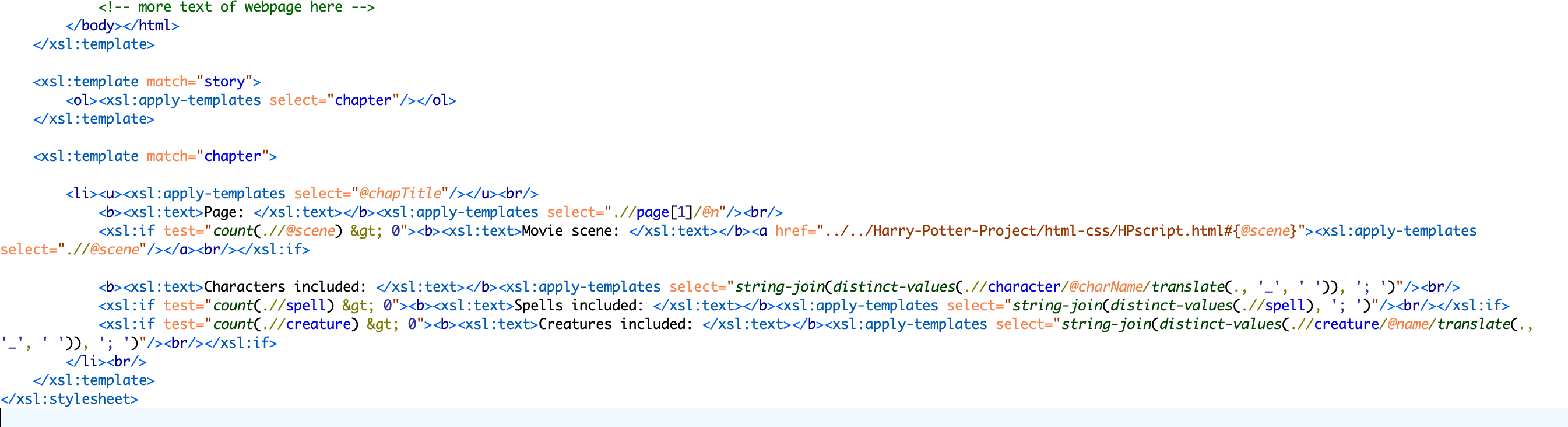
- The first template rule matched on the story element, which made it so that any other text outside of that element was not outputted. This was included in order to exclude the table of contents from this rule, as all we needed to match on was the text of the novel.
- In order to make a numbered list of the chapters, the the template rule matched on the attribute value included in every chapter element that inlcuded the name of the chapter.
- The link included outputs the scene number from the movie script that correlates with the chapter number of the novel. In order for this to work the corresponding scene had to be marked up in the original novel xml document. This also had to be associated in the schema so it would work when some chapter elements had the scene attribute and others did not. It then takes the viewer to that scene in the movie script page.
- The XSL:IF TEST rule was used to test that if there was a chapter that didn't have more than zero scenes, creatures, or spells in it, then it would not output the text included in the template rule.
- In order to output a semicolon separated list of characters, creatures, and spells, distinct-values was used to make sure that there were no repetitions of character/creature/spell names. String-join was then used to put those together in a list. '; ') was used to make this list separated by semicolons.
- For some of the attribute values extracted to make a list, the translate took was used to convert the underscores in the attribute values to spaces to make the list easier to read and more visually appealing.
BOOK SCHEMA